

Для многих в IT-сообществе 2022 год начался неудачно из-за ошибки в локальных версиях Microsoft Exchange Server, которая привела к зависанию писем в очереди из-за сбоя проверки даты. Проще говоря, ошибка, получившая название Y2K22 (в стиле бага Y2K, который напугал мир примерно четверть века назад), привела к тому, что программа не смогла обработать формат даты 2022 года. Исправление от Microsoft? Перевести дату обновлений антивирусных сигнатур на вымышленную 33 декабря 2021 года, чтобы дать значению даты достаточно «пространства для маневра», прежде чем оно достигнет максимального значения, которое может хранить базовый целочисленный тип.
Однако настоящий урок для разработчиков заключается в том, что реализация собственного кода для обработки дат сопряжена с чрезмерным риском совершения таких ошибок и изобретения странных исправлений с использованием вымышленных дат. Поэтому, если вы не пишете эти процедуры для операционной системы, компилятора и т. д., вам всегда следует использовать стандартные API для работы с датами.
Еще в 2015 году была обнаружена похожая ошибка, затронувшая программное обеспечение самолета Boeing 787 Dreamliner. Если бы ее не заметили и не исправили вовремя, ошибка могла привести к полной потере всего переменного электропитания, даже в полете, на борту самолета после 248 дней непрерывного питания. Решение, чтобы пилоты не теряли управление своим авиалайнером в воздухе? Перезагрузите свой 787 до истечения 248 дней, или, лучше, установите патч.
Так почему Microsoft пришлось делать вид, что обновления для ее антивирусного компонента Exchange по-прежнему из 2021 года? Зачем самолет нужно выключать и снова включать, чтобы он не разбился? В обоих случаях виной стало переполнение целых чисел — уязвимость, которая беспокоит все типы программного обеспечения, от видеоигр до GPS-систем и аэронавтики. В списке 2021 CWE Top 25 самых опасных программных слабостей, который анализировал около 32 500 CVE, опубликованных в 2019 и 2020 годах, переполнение или зацикливание целых чисел заняло двенадцатое место.
Неужели разработчики программного обеспечения настолько математически неграмотны, что не могут предвидеть, когда у них закончатся числа? На самом деле все сложнее. Давайте немного глубже разберемся, как компьютеры хранят и обрабатывают числа, чтобы понять, насколько неуловимым может быть переполнение целых чисел.
Что такое целое число?
В математике целые числа включают положительные числа, такие как 1, 2 и 3, число 0, а также отрицательные числа, такие как −1, −2 и −3. Целые числа не включают дроби или десятичные числа. Это означает, что множество всех целых чисел можно представить с помощью следующей числовой оси:

Обычно в языке программирования существует несколько типов целочисленных переменных — каждый из них хранит диапазон целочисленных значений в зависимости от количества бит, которое этот тип использует на конкретной машине. Чем больше бит потребляет целочисленный тип, тем большие значения могут быть в нем сохранены.
Рассмотрим целочисленные типы в языке программирования C, предполагая размеры бит, которые мы можем ожидать на типичной машине x64.
char занимает 8 бит памяти, что означает, что он может хранить следующие значения:
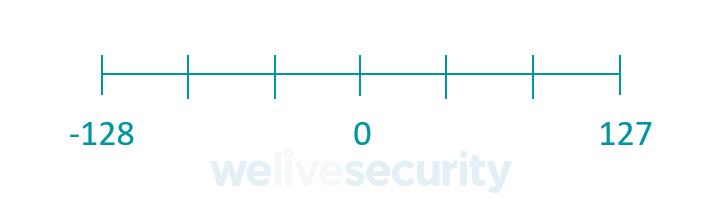
Обратите внимание, что char может хранить значения только от -128 до 127.
Но существует и другой «режим» целочисленного типа char, который хранит только неотрицательные целые числа:

Целочисленные типы имеют как знаковый, так и беззнаковый режимы. Знаковые типы могут хранить отрицательные значения, а беззнаковые — нет.
Следующая таблица показывает некоторые основные целочисленные типы в языке программирования C, их размеры на типичной машине x64 и диапазон значений, которые они могут хранить:
Таблица 1. Целочисленные типы, их типичные размеры и диапазоны для набора инструментов компилятора Microsoft C++ (MSVC)
| Тип | Размер (бит) | Диапазон |
|---|---|---|
| char | 8 | signed: −128 to 127 |
| #rowspan# | unsigned: 0 to 255 | |
| short int | 16 | signed: −32,768 to 32,767 |
| #rowspan# | unsigned: 0 to 65,535 | |
| int | 32 | signed: −2,147,483,648 to 2,147,483,647 |
| #rowspan# | unsigned: 0 to 4,294,967,295 | |
| long long int | 64 | signed: −9,223,372,036,854,775,808 to 9,223,372,036,854,775,807 |
| #rowspan# | unsigned: 0 to 18,446,744,073,709,551,615 |
Что такое переполнение целых чисел?
Переполнение или зацикливание целых чисел происходит, когда предпринимается попытка сохранить значение, которое слишком велико для целочисленного типа. Диапазон значений, которые могут быть сохранены в целочисленном типе, лучше представить в виде круговой числовой оси, которая зацикливается. Круговая числовая ось для знакового char может быть представлена следующим образом:
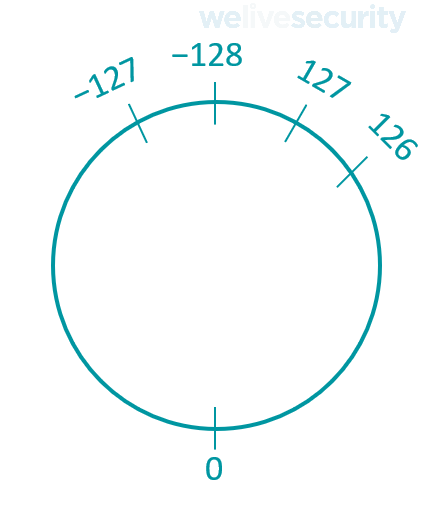
Если предпринята попытка сохранить число большее, чем 127, в знаковый char, счетчик зацикливается до −128 и продолжает движение вверх, к нулю, оттуда. Таким образом, вместо ожидаемого 128 сохраняется значение −128, вместо 129 — −127 и так далее.
Рассматривая проблему в обратном порядке, если предпринята попытка сохранить число меньшее, чем -128, в знаковый char, счетчик зацикливается до 127 и продолжает движение вниз, к нулю, оттуда. Таким образом, вместо ожидаемого −129 сохраняется значение 127, вместо −129 — 126 и так далее. Это иногда называют переполнением целого числа при вычитании.
Поиск неуловимого переполнения целых чисел
Представляя переполнение целых чисел как круг значений, которые зацикливаются, его становится довольно легко понять. Однако именно когда мы углубляемся в детали «приведения» целочисленных типов, а также переноса и компиляции программ, мы можем лучше понять некоторые проблемы, связанные с избежанием переполнения целых чисел.
Следите за приведениями типов
Иногда бывает полезно или даже необходимо сохранить значение в типе, отличном от исходного — приведение типов или «преобразование типов» позволяет программистам делать это. Хотя некоторые приведения безопасны, другие нет, поскольку они могут привести к переполнению целых чисел. Приведение считается безопасным, когда гарантируется сохранение исходного значения.
Безопасно приводить значение, хранящееся в целочисленном типе меньшего размера (с точки зрения ширины битов), к целочисленному типу большего размера в том же режиме — от меньшего беззнакового типа к большему беззнаковому типу и от меньшего знакового типа к большему знаковому типу. Таким образом, безопасно приводить от знакового char к знаковому short int, поскольку знаковый short int достаточно велик, чтобы хранить все возможные значения, которые могут быть сохранены в знаковом char:
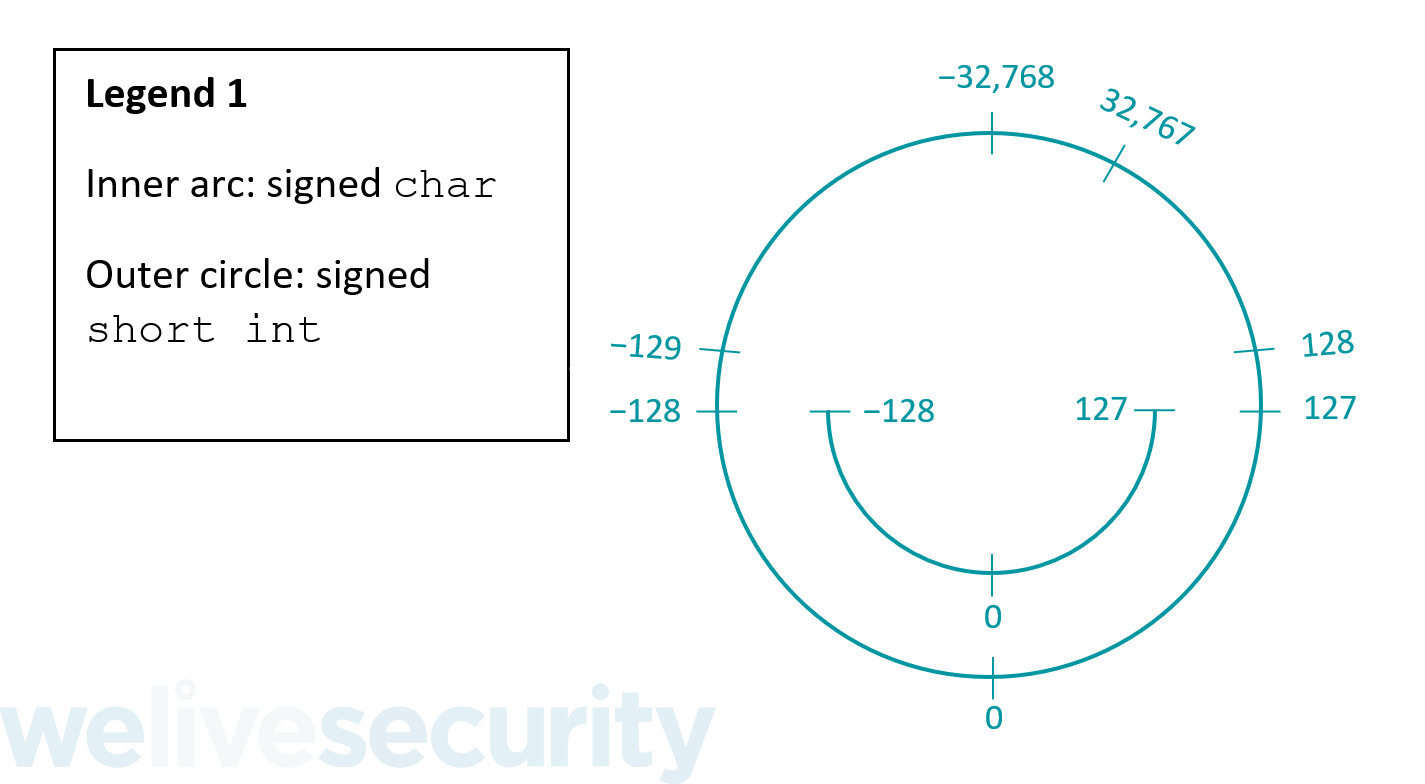
Приведение между знаковыми и беззнаковыми целыми числами является красным флагом для переполнения целых чисел, так как значения не могут гарантированно остаться прежними. При приведении от знакового типа к беззнаковому (даже если он больше) может произойти переполнение целого числа, поскольку беззнаковые типы не могут хранить отрицательные значения:

Все отрицательные знаковые значения char слева от красной линии на изображении выше, от −128 до −1, вызовут переполнение целого числа и превратятся в большие положительные значения при приведении к беззнаковому типу. −128 станет 128, −127 станет 129 и так далее.
И наоборот, при приведении от беззнакового типа к знаковому того же размера может произойти переполнение целого числа, поскольку верхняя половина положительных значений, которые могут быть сохранены в беззнаковом типе, превышает максимальное значение, которое может быть сохранено в знаковом типе такого размера.
Все большие положительные беззнаковые значения char слева от красной линии на изображении выше, от 128 до 255, вызовут переполнение целого числа и превратятся в отрицательные значения при приведении к знаковому типу того же размера. 128 станет −128, 129 станет −127 и так далее.
Приведение от беззнакового типа к знаковому типу большего размера более снисходительно, поскольку оно не несет риска переполнения целого числа: все значения, которые могут быть сохранены в меньшем беззнаковом типе, также могут быть сохранены в большем знаковом типе.
Неявные повышения типов: Остерегайтесь «предпочтения» 32 бит
Хотя возможность явного приведения целочисленных типов полезна, важно знать, как компиляторы неявно повышают операнды операторов (арифметических, бинарных, логических и унарных). Во многих случаях эти неявные повышения типов помогают предотвратить переполнение целых чисел, поскольку они повышают операнды до целочисленных типов большего размера перед их обработкой — фактически, базовая аппаратура обычно требует выполнения операций над операндами одного типа, и компиляторы будут повышать операнды меньшего размера до больших, чтобы достичь этой цели.
Однако правила неявного повышения типов отдают предпочтение 32-битным типам, что означает, что последствия для программиста иногда могут быть неожиданными. Правила следуют приоритету. Во-первых, если один или оба операнда являются 64-битными целочисленными типами (long long int), другой операнд повышается до 64 бит, если он еще не является таковым, и результат является 64-битным типом. Во-вторых, если один или оба операнда являются 32-битными целочисленными типами (int), другой операнд повышается до 32-битного типа, если он еще не является таковым, и результат является 32-битным типом.
Теперь здесь есть исключение из этого правила, которое может легко подвести программистов. Если один или оба операнда являются 16-битными типами (short int) или 8-битными типами (char), операнды повышаются до 32 бит перед выполнением операции, и результат является 32-битным типом (int). Единственными операторами, которые являются исключением из этого поведения, являются операторы инкремента и декремента до и после (++, —), что означает, что 16-битный (short int) операнд, например, не повышается, и результат также остается 16-битным.
«Предвзятое» повышение 8-битных и 16-битных операндов до 32 бит имеет решающее значение для понимания при проверке на переполнение целых чисел. Если вы думаете, что складываете два типа char или два типа short int, вы ошибаетесь, потому что они неявно повышаются до типов int и возвращают результат типа int. При 32-битном результате, возвращаемом операцией, необходимо понизить результат до 16 или 8 бит перед проверкой на переполнение целого числа. В противном случае существует риск необнаружения переполнения целого числа, поскольку int не переполнится при относительно малых значениях, которые short int или char могут предоставить в качестве операндов.
Проблемы переносимости кода I – разные компиляторы
Создание различных сборок программы, которые могут работать на разных архитектурах, является важным аспектом при проектировании программного обеспечения. Не только переписывание кода, плохо спланированного для различных сборок, может стать головной болью, но и может привести к переполнению целых чисел, если не принять меры предосторожности.
Компиляторы, которые используются для сборки кода для различных целевых машин, должны поддерживать стандарт языка программирования, но существуют определенные детали реализации, которые не определены и оставлены на усмотрение разработчиков компиляторов. Размеры целочисленных типов в C — одна из таких деталей, с лишь слабыми указаниями в стандарте языка C, что означает, что непонимание деталей реализации вашего компилятора и целевой машины — это рецепт возможной катастрофы.
Количество бит, потребляемых каждым целочисленным типом, описанным в Таблице 1, — это схема, используемая набором инструментов компилятора Microsoft C++ (MSVC), который включает C-компилятор при нацеливании на 32-битные, 64-битные и ARM-процессоры. Однако разные компиляторы, реализующие стандарт C, могут использовать разные схемы. Рассмотрим целочисленный тип, называемый long.
Для компилятора MSVC long
потребляет 32 бита независимо от того, является ли сборка для 32-битной или 64-битной программы. Однако для компилятора IBM XL C long потребляет 32 бита в 32-битной сборке и 64 бита в 64-битной сборке. Критически важно знать размеры, максимальные и минимальные значения, которые может хранить целочисленный тип, чтобы правильно проверять переполнение целых чисел для всех ваших сборок.
Проблемы переносимости кода II – разные сборки
Еще одна проблема переносимости, на которую следует обратить внимание, — это использование size_t, который является беззнаковым целочисленным типом, и ptrdiff_t, который является знаковым целочисленным типом. Эти типы потребляют 32 бита в 32-битной сборке и 64 бита в 64-битной сборке для компилятора MSVC. Фрагмент кода, который решает, следует ли ветвиться на основе сравнения, в котором один из операндов имеет один из этих типов, может привести программу по различным путям выполнения в зависимости от того, является ли она частью 32-битной или 64-битной сборки.
Например, в 32-битной сборке сравнение между ptrdiff_t и unsigned int означает, что компилятор приводит ptrdiff_t к unsigned int, и поэтому отрицательное значение становится большим положительным значением — переполнение целого числа, которое затем приводит к неожиданному пути выполнения программы или нарушению доступа. Но в 64-битной сборке компилятор повышает unsigned int до знакового 64-битного типа, что означает отсутствие переполнения целого числа и выполнение ожидаемого пути программы.
Как переполнение целых чисел приводит к переполнению буфера
Основной способ эксплуатации уязвимости переполнения целых чисел — это обход любых проверок, ограничивающих длину данных, которые должны быть сохранены в буфере, чтобы вызвать переполнение буфера. Это открывает двери для огромного массива методов эксплуатации переполнения буфера, которые приводят к дальнейшим проблемам, таким как повышение привилегий и выполнение произвольного кода.
Рассмотрим следующий искусственный пример:
#include <string.h> #include <stdio.h> #include <stdlib.h> int MAX_BUFFER_LENGTH = 11; // [1] char* initializeBuffer () { char* buffer = (char*) malloc(MAX_BUFFER_LENGTH * sizeof(char)); if (buffer == NULL) { printf("Could not allocate memory on the heapn"); } return buffer; } int main(void) { signed int buffer_length; char* source_buffer = "0123456789"; // Arbitrary test data char* destination_buffer = NULL; buffer_length = -1; // Hypothetical attacker-controlled variable printf("buffer_length as a signed int is %d and implicitly cast to an unsigned int is %un", buffer_length, buffer_length); // [2] Faulty size check if (buffer_length > MAX_BUFFER_LENGTH) { printf("Integer overflow detectedn"); } else { destination_buffer = initializeBuffer(); // [3] Potential buffer overflow due to integer overflow strncpy(destination_buffer, source_buffer, buffer_length); destination_buffer[buffer_length] = ' '; printf("Destination buffer contents: %sn", destination_buffer); } free(destination_buffer); return 0; }Не знакомы с C? Запустите этот код прямо в своем браузере с помощью блокнота в Google Colab.
В [2] нет проверки на отрицательные значения buffer_length, что означает, что она проходит проверку. Кроме того, MAX_BUFFER_LENGTH является знаковым int, но его следовало бы объявить в [1] как беззнаковый целочисленный тип, поскольку отрицательные значения никогда не должны использоваться при назначении длин буферов. Как беззнаковый целочисленный тип, компилятор неявно привел бы buffer_length к unsigned int при проверке в [2], что привело бы к обнаружению переполнения целого числа.
Но с −1, сохраненным в buffer_length, которое прошло проверку, и компилятором, неявно приводящим его как unsigned int в функции initializeBuffer в [3] вместо этого, оно переполняется до большого положительного значения около 4 миллиардов, далеко за пределом ожидаемой максимальной длины буфера 11.
Это переполнение целого числа затем напрямую приводит к переполнению буфера, поскольку strncpy пытается скопировать около 4 ГБ данных из исходного буфера в целевой буфер. Таким образом, хотя и предпринята попытка предотвратить переполнение буфера с помощью проверки размера в [2], проверка выполнена неправильно, и происходит переполнение целого числа, которое напрямую ведет к переполнению буфера.
При обработке приведений между знаковыми и беззнаковыми целочисленными типами недостаточно просто проверить размер значения, которое больше ожидаемого максимального значения. Также крайне важно проверять значение, которое меньше ожидаемого минимального значения:
// [2] Corrected size check if (buffer_length < 0 || buffer_length > MAX_BUFFER_LENGTH) {Практические правила
Различные стратегии могут быть использованы для проверки и обработки возможных переполнений целых чисел в вашем коде, некоторые из которых имеют компромисс между переносимостью и скоростью. Не вдаваясь в подробности, имейте в виду по крайней мере следующие рекомендации:
- По возможности отдавайте предпочтение беззнаковым целочисленным типам. Помните, нет смысла использовать знаковый целочисленный тип для выделения памяти, поскольку отрицательное значение в такой ситуации никогда не является допустимым.
- Просматривайте и тестируйте свой код, явно записывая все приведения, чтобы легче увидеть, где неявные приведения могут вызвать переполнение целых чисел.
- Включайте любые доступные в ваших компиляторах опции, которые могут помочь выявить определенные типы переполнений целых чисел. Например, компилятор GCC имеет опцию -ftrapv, которая проверяет знаковые переполнения целых чисел.
Переполнение целых чисел — это проблема, которая не исчезнет в ближайшее время. Действительно, существует множество старых Unix-подобных систем, у которых есть похожий на Y2K22 «запланированный» на 2038 год баг, который поэтому и называется Y2K38. До того, как 64-битные системы стали обычным явлением, доминировали 32-битные системы, что означало, что время Unix хранилось как знаковое 32-битное целое число. Поскольку время Unix начинает отсчет секунд с 00:00:00 UTC 1 января 1970 года, 32-битное время сможет охватить лишь несколько часов 19 января 2038 года, прежде чем произойдет зацикливание. К счастью, знание о проблеме заранее позволяет нам подготовиться и обновить многие уязвимые системы, прежде чем мы завершим круг и вернемся в 1901 год.